
Data Engineering Zoomcamp Final Project: End To End Data Pipeline in GCP
A 3 Months Long Journey of Learning and Growth in Data engineering

We can say that three months might feel really long, but it's surprising what you can achieve in that time. Sometimes days go by and all seem the same, making you feel stuck. I don't like that feeling. When someone asked how long the Data Engineering Zoomcamp is, which started on January 15th, I said, 'Twelve weeks.' It might sound like a lot, but during that time, I learned a lot and had fun.

What we learned?
I'd like to begin with a brief overview of what we learned and then implemented in our final project. If you are curious, have a look at my GitHub repository.
In our first module, we learned about two important concepts: Containerisation with Docker and Infrastructure as Code with Terraform. Docker simplifies the process of packaging applications and their dependencies into standardised units called containers. By adopting Terraform, we learned how to define and create infrastructure resources on GCP. This approach improves scalability, and makes everything repeatable and consistent across different environments.
In our second module, we learned about Orchestration, a critical aspect of managing data pipelines efficiently. We began by understanding the concept of a Data Lake, a centralised repository that allows us to ingest, store and analyse our datasets. Next, we discovered Mage, a great tool for orchestrating workflows. With Mage, we were able to define, schedule and execute our data workflows with ease.
In our third module, we went through Data Warehousing and understanding of BigQuery's capabilities and best practices. We explored advanced techniques such as Partitioning and Clustering, which optimize data within BigQuery tables for improved query performance and cost efficiency.
In our fourth module, we began with an exploration of the Basics of Analytics Engineering like designing, building, and maintaining data pipelines for analytics and reporting purposes. We used a dbt (Data Build Tool), an open-source tool designed specifically for analytics engineering workflows. dbt enables analysts and engineers to transform raw data into analytics-ready datasets using SQL-based transformations, version-controlled models, and automated testing.
Ready to accelerate your data engineering career? Check out this comprehensive guide "Python Data Engineering Resources" - packed with 100+ carefully selected tools, 30+ hands-on projects, and access to 75+ free datasets and 55+ APIs.
Get a free sample chapter at futureproofskillshub.com/python-data-engineering. Available in paperback on Amazon, and as an ebook on Apple Books, Barnes & Noble, and Kobo.
Master the complete tech stack atfutureproofskillshub.com/books – from AI to Python, SQL, and Linux fundamentals. Plus, discover how to maintain peak performance and work-life balance while advancing your technical career in "Discover The Unstoppable You".
In our fifth module, we began by understanding the concept of Batch Processing, a method for processing large volumes of data in batches or chunks. For this, we used Apache Spark, a powerful distributed computing framework designed for processing large-scale datasets across clusters of computers. We explored Spark's DataFrame API and Spark SQL, which offer simple ways to handle structured data in Spark.
In our last module, we went through Streaming, Kafka, and its ecosystem components necessary to design and implement real-time data processing solutions.
We also had two really great workshops in between. The first one was about dlt(Data Load Tool) and the second one was about RisinglWave and how to process real-time streaming data using SQL.
If you are interested in more details about every module and workshops you can find it here.
Final Project
The goal of this project was to apply everything we learned in this course and build an end-to-end data pipeline.
Project Highlights:
✅ Built an end-to-end data pipeline using Python.
✅ Fetched data from Open-Meteo APIs for Air Quality and Weather Forecast.
✅ Automated infrastructure provisioning with Terraform
✅ Deployed on Google Cloud Platform (GCP), and loaded data using services like BigQuery and Cloud Storage.
✅ Orchestrated the entire pipeline to run smoothly with Mage.Ai.
✅ Created dashboards in GCP with Looker
Problem Statement:
The primary task was to aggregate historical and forecasted data from different sources, enabling detailed analysis and forecasting for different regions.
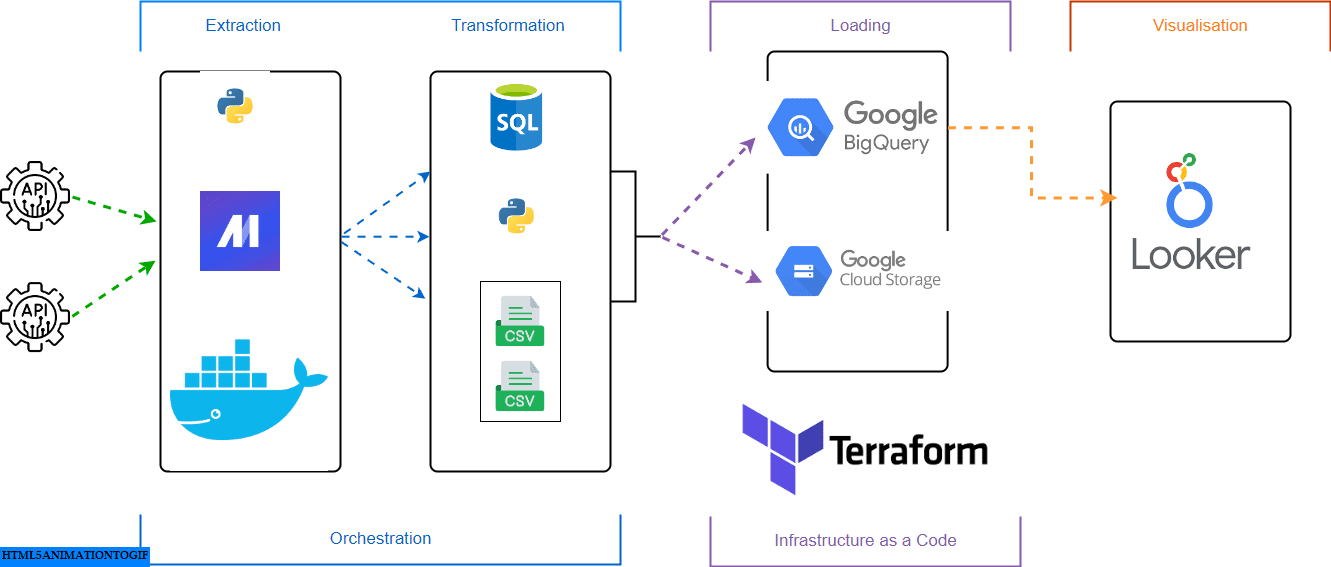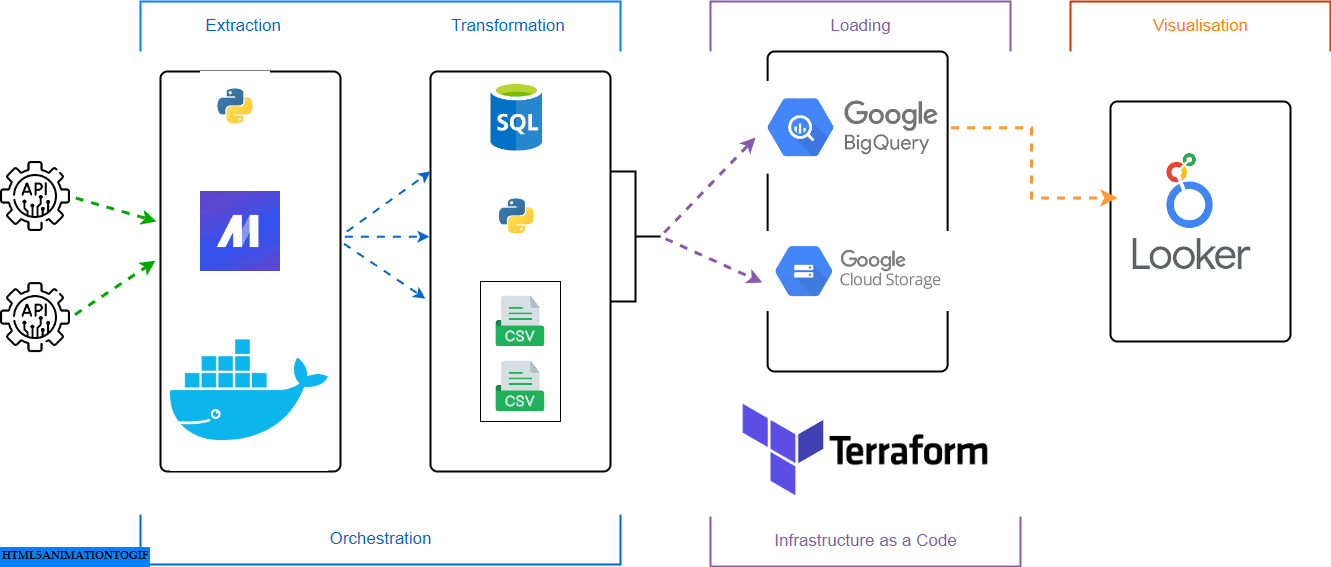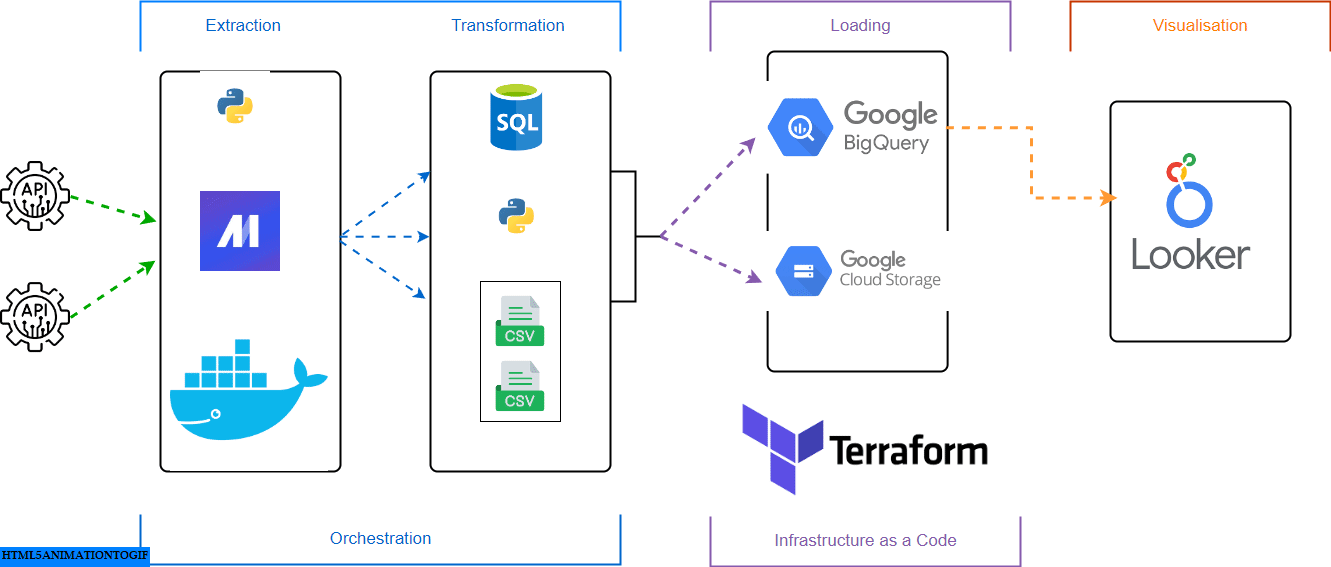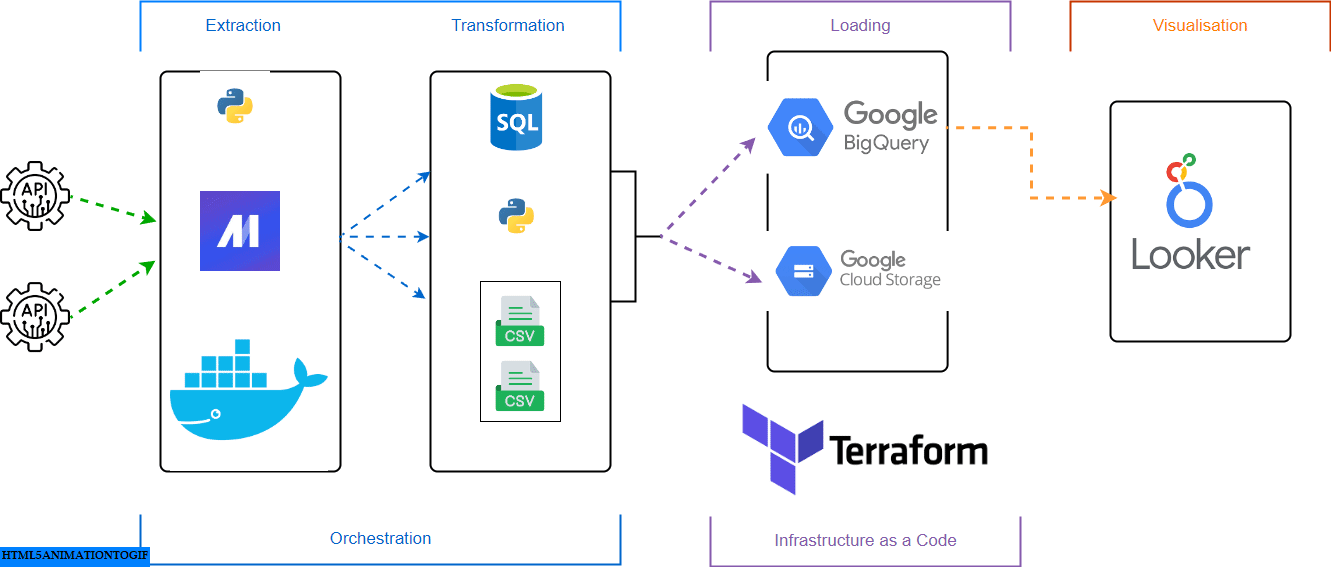
Prerequisites
Before running the code you need to follow the steps below.
Setting up GCP
Google Cloud is a suite of Cloud Computing services offered by Google that provides various services like compute, storage, networking, and many more. It is organised into Regions and Zones.
Setting up GCP would require a GCP account. A GCP account can be created for free on trial but would still require a credit card to sign up.
Start by creating a GCP account at this link
Navigate to the GCP Console and create a new project. Give the project an appropriate name and take note of the project ID.
Create a service account:
In the left sidebar, click on "IAM & Admin" and then click on "Service accounts."
Click the "Create service account" button at the top of the page.
Enter a name for your service account and a description (optional).
Select the roles you want to grant to the service account. For this project, select the BigQuery Admin, Storage Admin, and Compute Admin Roles.
Click "Create" to create the service account.
After you've created the service account, you need to download its private key file. This key file will be used to authenticate requests to GCP services.
Click on the service account you just created to view its details.
Click on the "Keys" tab and then click the "Add Key" button.
Select the "JSON" key type and click "Create" to download the private key file. This key would be used to interact with the Google API from Mage.
Store the JSON key as you please, but then copy it into the mage directory of this project and give it exactly the name my-airquality-credentials.json.
This application communicates with several APIs. Make sure you have enabled the BigQuery API.
Go to BigQuery API and enable it.
Running the Code
Note: these instructions are used for macOS/Linux/WSL, for Windows it may differ
Clone this repository
cd into the terraform directory. We are using Terraform to create Google Cloud resources. My resources are created for the EU. If needed, you can change it in the variables.tf file. In this file, you need to change the project ID to the project ID you created in GCP.
To prepare your working directory for other commands we are using:
terraform initTo show changes required by the current configuration you can run:
terraform planTo create or update infrastructure we are using:
terraform applyTo destroy previously-created infrastructure we are using:
terraform destroyIMPORTANT: This line is used when you are done with the whole project.
cd into the mage directory
Rename
dev.envto simply.env.Now, let's build the container
docker compose buildFinally, start the Docker container:
docker compose upWe just initialised a mage repository. It is present in your project under the name air-quality. Now, navigate to http://localhost:6789 in your browser!
Time to work with a mage. Go to the browser, find pipelines, click on
air_quality_api pipelineand click onRun@once.

IMPORTANT: For some reason, an error may occur during the step of creating the 'air_aggregated' table, indicating '404 Not Found: Table air-quality-project-417718:air_quality.air_aggregated_data was not found in location EU.' However, if you navigate to BigQuery and refresh the database, the table should appear.
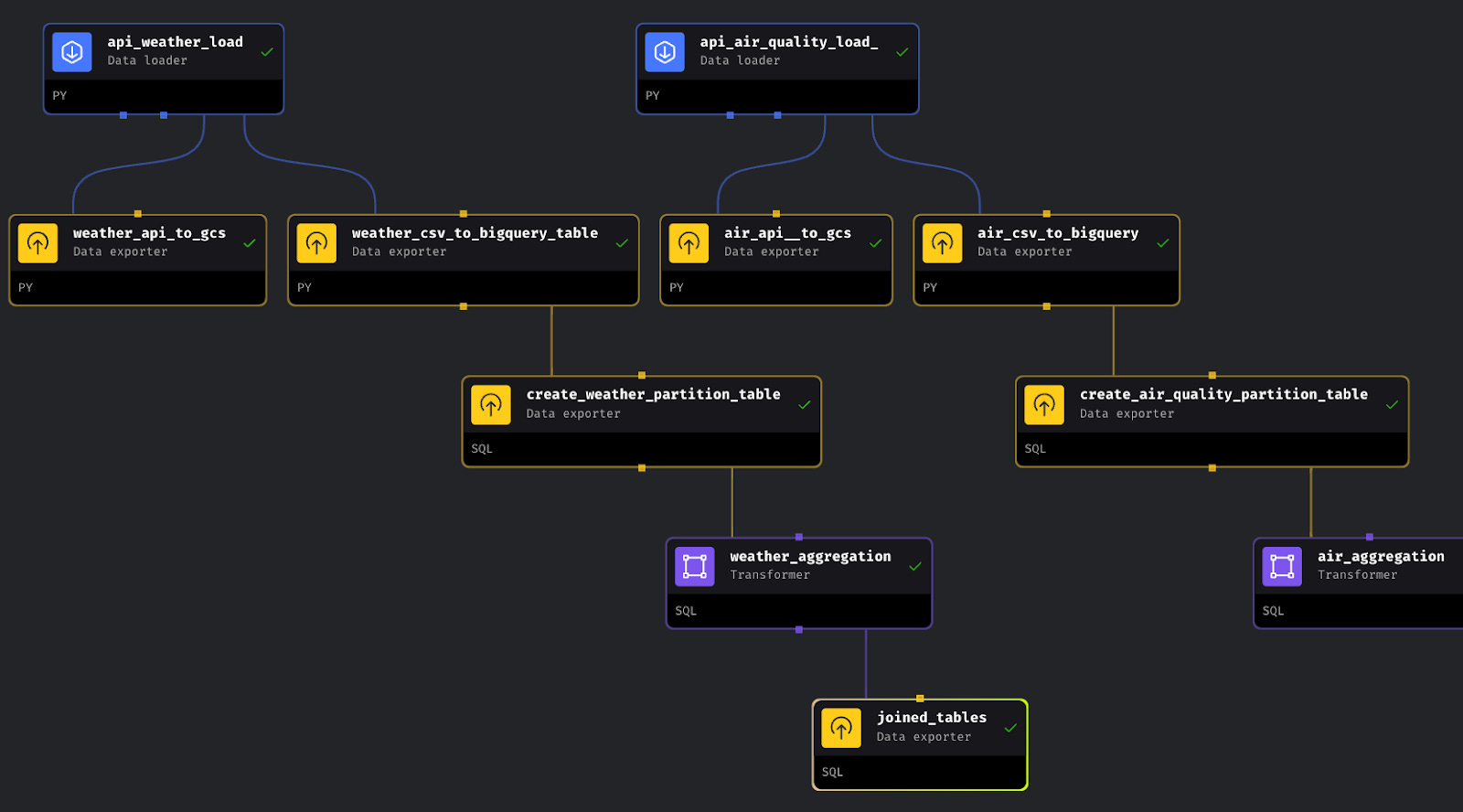
When you are done, in a Google bucket you should have two CSV files and in the BigQuery you should have all tables. Your pipeline should look like this:
Creating Visualisations
With your Google account, log in at Google Looker Studio
Connect your dataset using the Big Query Connector
Select your project name then select the dataset. This would bring you to the dashboard page
Create your visualisations and share.

Conclusion
In conclusion, the Data Engineering Zoomcamp has been an incredible experience. Over the span of twelve weeks, we covered a variety of topics, from Docker and Terraform to orchestration tools like Mage. Through hands-on learning, we gained valuable skills necessary for building effective data pipelines.
The final project was the culmination of the effort, allowing me to apply my knowledge in a real-world scenario. By fetching data from diverse sources, automating infrastructure setup with Terraform, and deploying on the Google Cloud Platform, I've demonstrated my ability to implement complex challenges head-on.
Even though there were challenges along the way, the feeling of achievement and personal growth has made the experience very rewarding. With these new skills, I feel confident about future data engineering projects.
For more insights into my projects, feel free to explore my GitHub repository.