
Data Engineering Zoomcamp week 6: RisingWave workshop
The workshop showed the exciting capabilities of RisingWave for real-time data processing and analytics.

Hello Data Enthusiasts!
I'm excited to share insights from our last workshop in Data Engineering Zoomcamp focused on how to process real-time streaming data using SQL in RisingWave, led by the knowledgeable Noel Kwan from RisingWaveLabs.
If you missed it, don't worry - the entire workshop has been recorded and is available on YouTube.
In this Workshop the following topics were covered and learned:
How to ingest data into RisingWave using Kafka
How to process the data using Materialised Views
Using Aggregations
Using Temporal Filters
Using Window Functions (Tumble)
Using Joins
Layering MVs to build a stream pipeline
How to sink the data out from RisingWave to Clickhouse
Introducing RisingWave
RisingWave is an open-source SQL database for processing and managing streaming data. It's designed to handle high-throughput, real-time data ingestion and processing, allowing users to analyse and query streaming data with SQL, thanks to its PostgreSQL-style interaction experience.
This type of database is often used in applications where real-time insights are critical, such as in financial trading, IoT (Internet of Things) systems, and monitoring and analytics platforms.
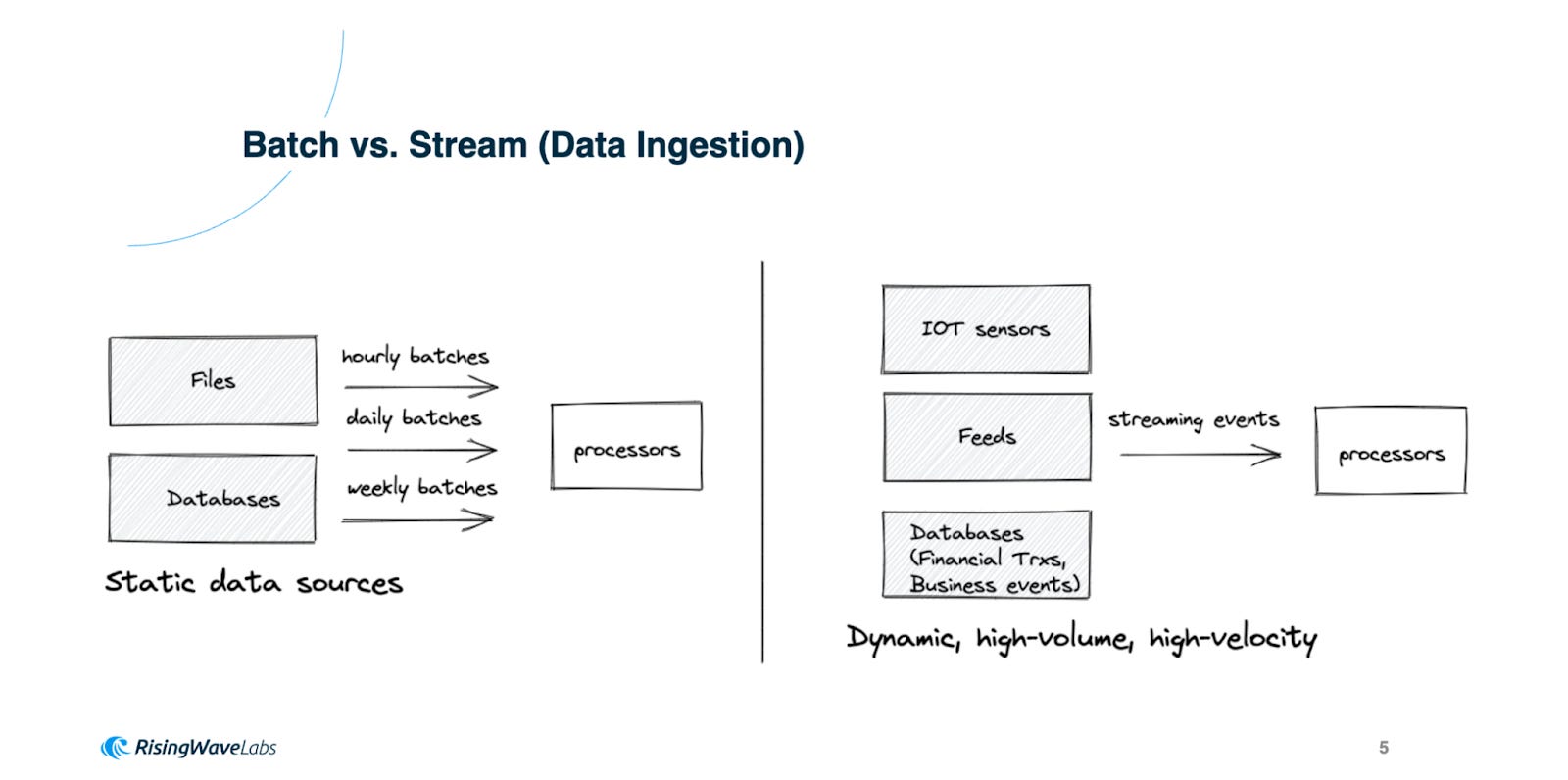
You can use RisingWave when you need to analyse and act on real-time data streams using SQL, whether it's for monitoring, alerting, or historical analysis. It's a powerful tool for businesses that rely on real-time insights to make decisions and stay competitive.
Level up your database skills with "SQL Crash Course" - featuring 350+ practical examples and 140+ interview questions with solutions. Includes a complete e-commerce database for hands-on practice. Get your free sample chapter at futureproofskillshub.com/sql-crash-course. Find the paperback on Amazon, or grab the ebook on Apple Books, Barnes & Noble, and Kobo.
Master the complete tech stack at futureproofskillshub.com/books – from AI to Python, SQL, and Linux fundamentals. Plus, discover how to maintain peak performance and work-life balance while advancing your technical career in "Discover The Unstoppable You".
Imagine you have a business that collects a lot of data in real-time, like sales transactions, website clicks, or sensor readings from IoT devices. You want to analyse this data as it comes in to make quick decisions or generate real-time reports.
This is where RisingWave comes in. It allows you to store and process this streaming data using SQL, which is a language many people are already familiar with. You can use RisingWave to:
Run SQL queries on the data as it's being collected. For example, you could calculate sales trends, monitor website traffic, or detect anomalies in sensor readings in real-time.
Set up alerts to notify you when certain conditions are met. For instance, you could receive an alert if sales suddenly drop, website traffic spikes, or if a sensor detects a critical issue.
Store the streaming data for historical analysis. This allows you to analyse trends over time, identify patterns, and make long-term decisions based on historical data.
Scale up to handle the increased load. It distributes the data processing across multiple nodes, so it can handle large volumes of data without slowing down.
Exercises
Prerequisites
Clone repository.
git clone git@github.com:risingwavelabs/risingwave-data-talks-workshop-2024-03-04.git cd risingwave-data-talks-workshop-2024-03-04Docker and Docker Compose
Python 3.7 or later
pip and virtualenv for Python
psql (I use PostgreSQL-14.11)
psql is a command-line interface for interacting with PostgreSQL databases. I’m using MacOS, so before you begin, make sure that you have Homebrew installed on your Mac. To install psql run the following command:
brew install postgresqlThis will install the latest version of PostgreSQL, along with the psql command-line interface. The installation process may take a few minutes to complete. Once the installation is complete, you can verify that psql is working by running the following command:
psql --versionThis should display the version number of psql that you have installed.

For this workshop, we were using the NYC Taxi dataset. This dataset is a public dataset and contains information about taxi trips in New York City.
The following files have already been downloaded and are available in the data directory:
yellow_tripdata_2022-01.parquet
taxi_zone.csv
Setting up RisingWave with Docker Compose
The docker-compose.yml file is located in the docker directory and contains the following key components:
RisingWave (Stream Processing)
Clickhouse (Downstream Delivery)
Redpanda (Upstream Ingestion)
Grafana (Visualization)
Prometheus (Metrics)
MinIO (Storage)
Etcd (Metadata Storage)
Getting Started
Setup our python environment.
# Setup python
python3 -m venv .venv
source .venv/bin/activate
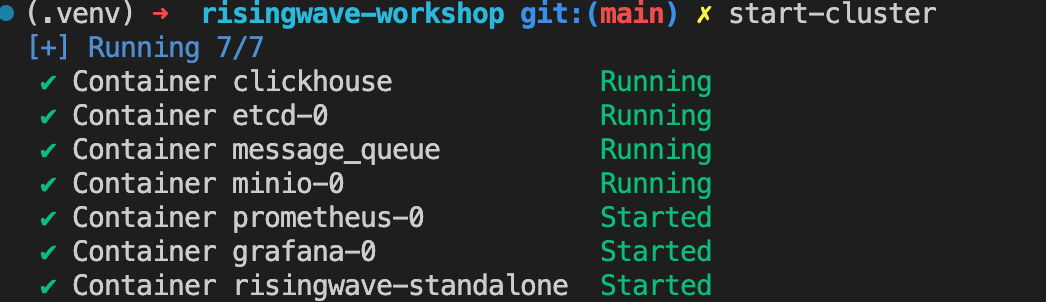
pip install -r requirements.txtStart the RisingWave cluster.
source commands.sh
# Start the RW cluster
start-clusterstart-cluster reads these lines from commands.sh file:
# Starts the risingwave cluster
start-cluster() {
docker-compose -f docker/docker-compose.yml up -d
}
Ingesting Data into RisingWave using Kafka
The seed_kafka.py file contains the logic to process the data and populate RisingWave.
In this workshop, in order to simulate real-time data the timestamp fields in the trip_data were replaced with timestamps close to the current time. That's because yellow_tripdata_2022-01.parquet contains historical data from 2022.
Let's start ingestion into RisingWave by running it:
stream-kafkastream-kafka reads lines from commands.sh file:
# Seed trip data from the parquet file
stream-kafka() {
./seed_kafka.py update
}Right now we're using a confluent client for sending the records from the parquet file to our Kafka topic.
Let that run in the background. Open another terminal to create the trip_data table. Activate your .venv and run these commands:
source commands.sh
psql -f risingwave-sql/table/trip_data.sqlYou may look at their definitions by running:
psql -c 'SHOW TABLES;
Validating the ingested data
Now we are ready to begin processing the real-time stream being ingested into RisingWave!
The first thing we will do is to check taxi_zone and trip_data, to make sure the data has been ingested correctly.
Let's start a psql session.
source commands.sh
psqlFirst, we can verify taxi_zone, since this is static data:
SELECT * FROM taxi_zone;
Now, we can verify trip_data:
SELECT * FROM trip_data;
For additional exercises, you can follow the instructions provided on this page.
What's next? Homework!
For the homework, we used historical data from the dataset.
Run the following commands:
# Exit a psql session.
exit# Load the cluster op commands.
source commands.sh
# First, reset the cluster:
clean-cluster
# Start a new cluster
start-cluster
# Seed historical data instead of real-time data
seed-kafka
# Recreate trip data table
psql -f risingwave-sql/table/trip_data.sql
# Check that you have 100K records in the trip_data table# You may rerun it if the count is not 100K
psql -c "SELECT COUNT(*) FROM trip_data"
We had three questions. Here, I will show you just the last question. You can find the rest in my repository.
Question 3:
From the latest pickup time to 17 hours before, what are the top 3 busiest zones in terms of number of pickups? For this question, 17 hours were picked to ensure we have enough data to work with.
SELECT
tz.zone AS pickup_zone,
COUNT(*) AS num_pickups
FROM
trip_data td
JOIN
taxi_zone tz ON td.pulocationid = tz.location_id
WHERE
td.tpep_pickup_datetime >= (SELECT MAX(tpep_pickup_datetime) - INTERVAL '17 hours' FROM trip_data)
AND td.tpep_pickup_datetime <= (SELECT MAX(tpep_pickup_datetime) FROM trip_data)
GROUP BY
tz.zone
ORDER BY
num_pickups DESC
LIMIT 3;Result:

Conclusion
The RisingWave workshop was a great learning experience! The workshop showed the exciting capabilities of RisingWave for real-time data processing and analytics. I am grateful for the opportunity to learn about it and happy to share the knowledge further! I feel like I learned so much about real-time data processing.
Intrigued to learn more about RisingWave and its capabilities? Dive into the documentation to explore its functionalities.
So, Data Engineers keep coding and keep exploring.