I’m excited to share insights from Module 6, where we learned how Kafka works internally and then practiced setting up Spark and Kafka clusters locally with Docker and by using the Confluence SaaS that runs a Kafka cluster in the cloud.
What is stream processing?
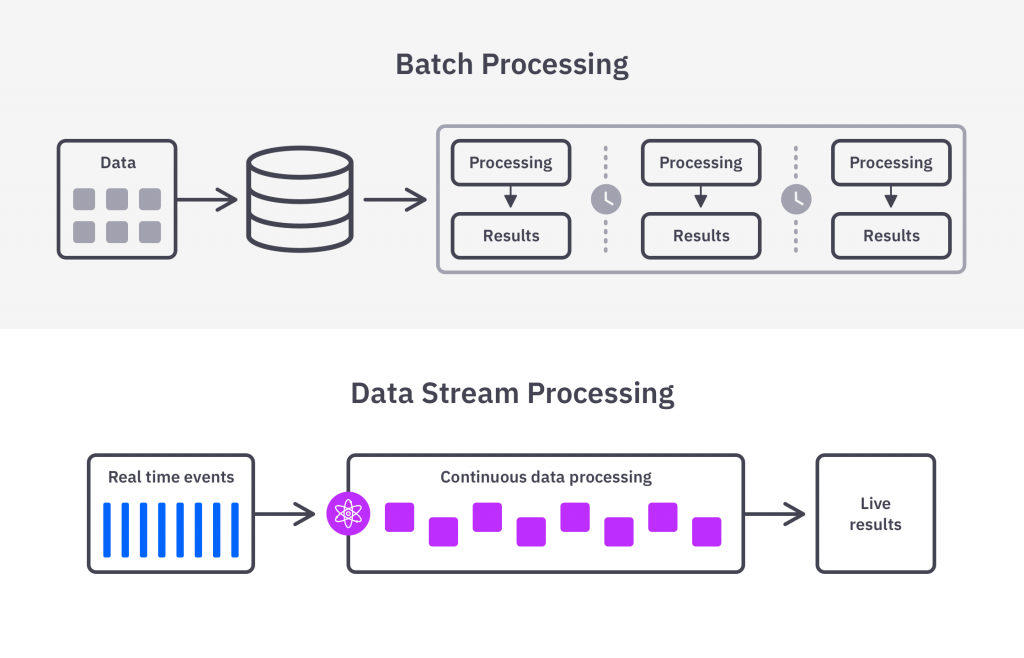
Stream processing is a method of computer data processing where continuous streams of data are processed in real-time as they are received. Instead of processing data in batches or chunks, as is common in traditional batch processing, stream processing deals with data items individually or in small groups as they arrive.
Here's a breakdown of key aspects:
Stream processing deals with data that flows continuously, such as data from log files, financial transactions, social media feeds, or any other source that generates a constant stream of information.
The goal of stream processing is often to analyse, transform, or react to incoming data immediately or with minimal delay. This real-time aspect is crucial for applications where timely insights or actions are necessary.
In many cases, stream processing involves maintaining some form of state across the incoming data stream. This state could include aggregations, session information, or any other context necessary for processing the data effectively.
Stream processing systems are often designed to be highly scalable and fault-tolerant. They should be able to handle increasing data volumes without sacrificing performance and should continue operating smoothly in the event of failures or network issues.
Popular stream processing frameworks and tools include Apache Kafka, Apache Flink, Spark Streaming, and others. These frameworks provide the infrastructure and abstractions necessary for developers to build and deploy stream processing applications efficiently.
What is Apache Kafka?
Apache Kafka is an open-source distributed event streaming platform initially developed by LinkedIn and later open-sourced as part of the Apache Software Foundation. It is designed to handle high-throughput, fault-tolerant, and scalable event streaming in real-time.
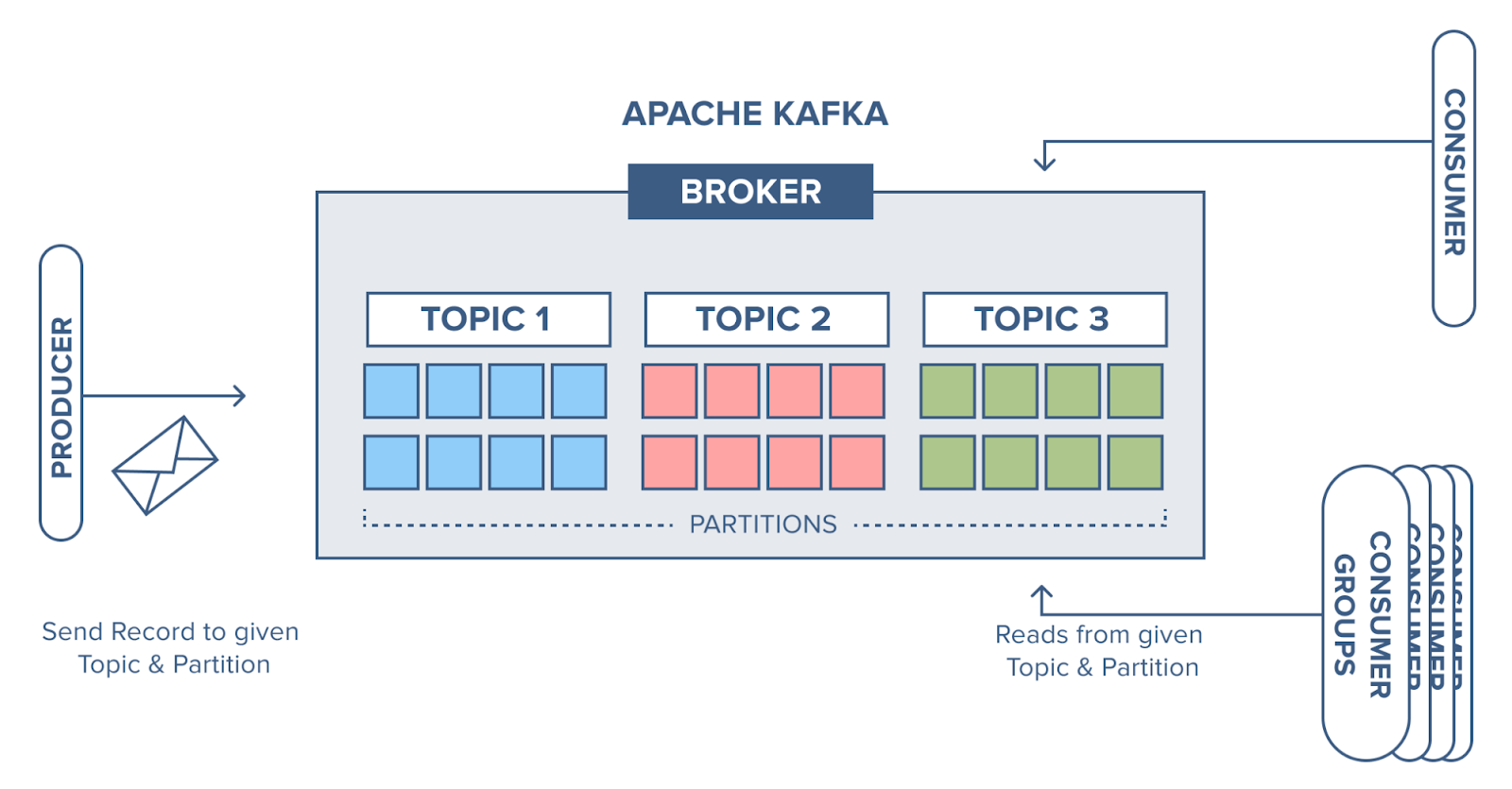
Kafka serves as a distributed messaging system or a distributed log, where data is organised into topics. Producers publish records (messages) to topics, and consumers subscribe to these topics to consume the data.
To understand those new terms I’m going to try to explain them in an easy way:
Topics: Think of a topic as a labeled container for messages in Kafka. It's like a channel where data is organised and stored. Each topic has a name that describes the kind of data it holds, such as "rides" or "user-actions". Producers publish messages to topics and consumers subscribe to topics to read those messages.
Producers are the ones who send messages to Kafka topics. They can be any system or application that generates data. For example a web server logging user activity. Producers write messages to Kafka topics and don't worry about who reads them.
Consumers are the ones who read messages from Kafka topics. They are like listeners or subscribers waiting to receive updates. Consumers can be applications, services, or processes that need to process or analyse the data. They subscribe to specific topics and receive messages as they're published. For instance, an analytics service might consume user activity logs to generate reports.
Message is a unit of data that is sent from a producer to a topic. You can think of a message as a small package of information containing whatever data the producer wants to send. It could be a piece of text, a number, a file, or any other kind of data.
Here's a simple analogy: Imagine you have a mailbox (which is like a Kafka topic), and you're the owner of the mailbox (like a Kafka broker). People (producers) can drop letters (messages) into your mailbox. Each letter contains some information, like a message from a friend, a bill, or an invitation.
Kafka is built to scale horizontally across multiple nodes or servers. This allows it to handle large volumes of data and high throughput by distributing the data and processing it across multiple brokers (Kafka servers).
Ready to accelerate your data engineering career? Check out this comprehensive guide "Python Data Engineering Resources" - packed with 100+ carefully selected tools, 30+ hands-on projects, and access to 75+ free datasets and 55+ APIs.
Master the complete tech stack atfutureproofskillshub.com/books – from AI to Python, SQL, and Linux fundamentals. Plus, discover how to maintain peak performance and work-life balance while advancing your technical career in "Discover The Unstoppable You".
Ensures fault tolerance by replicating data partitions across multiple brokers. This replication ensures that data is not lost even if some brokers or nodes fail. Kafka also supports automatic leader election and partition reassignment to maintain availability in case of failures.
Kafka enables real-time processing of data streams. It allows producers and consumers to work with data as it becomes available, making it suitable for use cases that require low-latency processing and real-time analytics.
Published records are retained on Kafka for a configurable period, allowing consumers to replay messages or go back in time to retrieve past data. This durability feature is crucial for scenarios where data needs to be stored and processed over an extended period.
Kafka provides robust integration capabilities with various systems and frameworks. It supports connectors for integrating with databases, messaging systems, data lakes, stream processing frameworks (like Apache Flink or Apache Spark) and more.
Kafka Streams
Kafka Streams is like a special toolkit that helps you work with data in Kafka in a really smart way. Normally, when you work with data in Kafka, you write separate programs to produce, consume, and process data. But with Kafka Streams, you can do all of that processing right within Kafka itself, without needing extra tools or systems. It's like having a mini-factory inside Kafka that transforms, filters, or analyses data as it moves through.
Kafka Streams lets you perform these transformations and analyses in real-time, as messages are flowing through Kafka. So, if you're keeping track of website clicks, you can instantly count how many clicks you've received in the last minute, or if you're analysing sensor data, you can immediately spot any unusual patterns as they happen.
Just like Kafka itself, Kafka Streams is designed to be scalable and fault-tolerant. So, whether you're processing thousands of messages a second or dealing with unexpected hiccups in your system, Kafka Streams can handle it with ease.
Some of the main features of Kafka Streams include:
Data Transformation – Transform, filter, and enrich data streams in real-time.
Time window processing: Analyze data in defined time windows, making it easy to detect patterns and trends in data streams.
Join – Combine data streams from multiple sources to obtain more complete and accurate information.
Aggregation – Perform calculations on data streams in real-time, such as counting events or summing values.
In this module, we covered a variety of topics, including Confluent Cloud, the fundamentals of Kafka Streams, stream joins, testing methodologies, windowing operations, Kafka KSQLDB & Connect, and the Kafka Schema Registry in Java. However, for this newsletter, I will be focusing specifically on PySpark Streaming.
Docker module includes Dockerfiles and docker-compose definitions to run Kafka and Spark in a docker container.
Follow next steps:
Start Docker desktop
Move to the build directory:
cd docker/spark
Build up the images:
chmod +x build.sh ; ./build.sh
chmod +x build.sh: This part of the command changes the permissions of the file named build.sh to make it executable. The chmod command stands for "change mode," and the +x option makes the file executable by granting execute permission to the owner of the file.
./build.sh: This part of the command executes the file build.sh. The ./ before the file name specifies that the file is located in the current directory. By running ./build.sh, you're executing the script or program named build.sh in the current directory.
Create the network so that the Kafka and Spark Docker containers that we are going to create have connectivity with each other:
Stop Docker-Compose (within for kafka and spark folders)
Kafka folder:
docker compose down
Spark folder:
docker compose down
If you want to see if you have some Docker containers that are currently running on your system use this command:
docker ps
Conclusion
This module was the culmination of our journey. Exploring concepts like topics, producers, consumers, and messages has equipped us with a deeper understanding of Kafka's architecture and functionalities.
With one more workshop and a final project on the horizon, there's still much ground to cover and many technologies and solutions to explore.
Personally, I'm thrilled and grateful about the knowledge we got and future prospects made possible by acquiring these skills.
So, Data Engineers keep coding and keep exploring.