
Understanding Data Pipelines
A Guide for Data Engineers

Understanding data pipelines is fundamental for every data engineer. Great. But why, you may wonder? Simply because they are the backbone of efficiently managing and processing data, enabling its transformation into valuable insights for businesses, and automating repetitive tasks to save time and reduce errors.

What is a Data Pipeline?
It's a sequence of steps that automatically moves and processes data from its source to its destination, such as databases or data warehouses, ensuring that it's cleaned, transformed, and ready to be used for various purposes like analysis, reporting, or storage.
Here's an overview of what you should know about data pipelines along with some best practices:
Data Pipeline Components:
Ingestion: Acquiring data from various sources like databases, APIs, logs, or streaming platforms.
Processing: Manipulating, cleaning, and transforming data to make it usable for analysis.
Storage: Storing data in appropriate repositories like databases, data lakes, or warehouses.
Transportation: Moving data between different components of the pipeline efficiently and reliably.
Monitoring and Logging: Implementing systems to monitor pipeline health, track data flow, and log errors.
Ready to accelerate your data engineering career? Check out this comprehensive guide "Python Data Engineering Resources" - packed with 100+ carefully selected tools, 30+ hands-on projects, and access to 75+ free datasets and 55+ APIs.
Get a free sample chapter at futureproofskillshub.com/python-data-engineering. Available in paperback on Amazon, and as an ebook on Apple Books, Barnes & Noble, and Kobo.
Master the complete tech stack atfutureproofskillshub.com/books – from AI to Python, SQL, and Linux fundamentals. Plus, discover how to maintain peak performance and work-life balance while advancing your technical career in "Discover The Unstoppable You".
Tools and Technologies: Become proficient in using tools and technologies commonly used in building data pipelines, such as Apache Kafka, Apache Airflow, Mage.AI, and others, or custom-built solutions using programming languages like Python or Java.
Data Pipeline Architectures:
Batch Processing: Handling data in discrete batches at regular intervals.
Stream Processing: Processing data in real-time or near real-time.
ETL (Extract, Transform, Load): The traditional approach involves extracting data from sources, transforming it, and loading it into the destination.
ELT (Extract, Load, Transform): Loading raw data into the destination first and then performing transformations as needed.
Scalability: With the increasing volume of data generated every day, scalability is crucial. Data pipelines can scale to handle growing data volumes and adapt to changing business needs, allowing your data infrastructure to grow.
Optimized Performance: By designing and optimizing data pipelines, you can improve the performance of data processing tasks, reducing latency and ensuring that data is delivered to its destination quickly and efficiently.

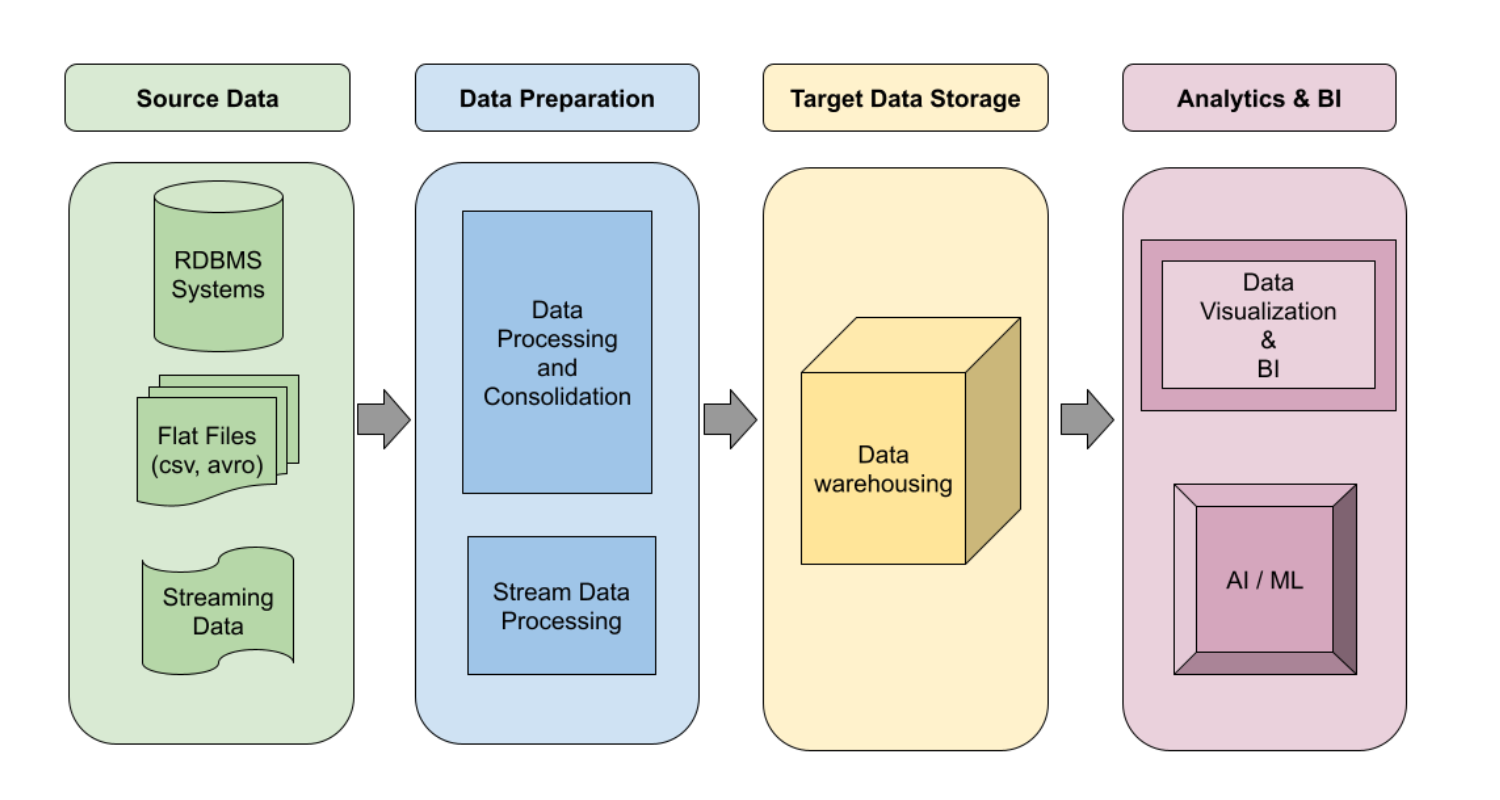
How does it work?
Let's try with this example to illustrate how data pipelines work in a real-world scenario:
Scenario: E-commerce Sales Analysis
Imagine you work for an e-commerce company that sells a variety of products online. Your job is to analyze sales data to identify trends, optimize marketing strategies, and improve overall business performance. Here's how data pipelines come into play:
1. Source:
The data originates from multiple sources:
Online transaction records stored in a PostgreSQL database.
Website analytics data collected by Google Analytics.
Customer feedback and reviews from various social media platforms.
For example: A Python script connects to the PostgreSQL database and retrieves the latest transaction records using SQL queries. Simultaneously, another script pulls website analytics data from the Google Analytics API and gathers social media feedback using API endpoints.
2. Processing:
Once the data is extracted from these sources, it’s time for processing:
Transaction records are cleaned to remove any duplicates or errors.
Website analytics data is aggregated to calculate metrics like page views, bounce rates, and conversion rates.
Customer feedback is analyzed using natural language processing (NLP) techniques to extract sentiment and identify key topics.
3. Destination:
The transformed data is then loaded into a data warehouse, such as Amazon Redshift or Google BigQuery, where it's organized into tables for easy querying and analysis. Visualization tools like Tableau or Power BI can connect to the data warehouse to create dashboards to monitor sales performance and customer feedback.
Challenges and Best Practices:
Challenges: Ensuring the pipeline can handle large volumes of data during peak shopping seasons, maintaining data quality and consistency across different sources, and monitoring pipeline health to prevent failures.
Best Practices: Implementing automated testing to catch errors early, documenting the pipeline architecture and data flows comprehensively.
Conclusion
The data pipeline eliminates the manual and time-taking steps. By understanding these concepts and best practices, you'll be well-equipped to design, build, and maintain robust and efficient data pipelines as a data engineer.
So put some effort into learning and understanding the data pipeline, because this knowledge is one of the most important in modern data engineering work.